当社のコア技術について
社内の会計システムや、CRM、
チャネル毎のサブシステムなど、
様々なデータベースを
仮想的につなげて比較可能に。
DYNATREKが
お客様のDX推進を
加速します。

DYNATREKのコア技術:仮想データベース技術について
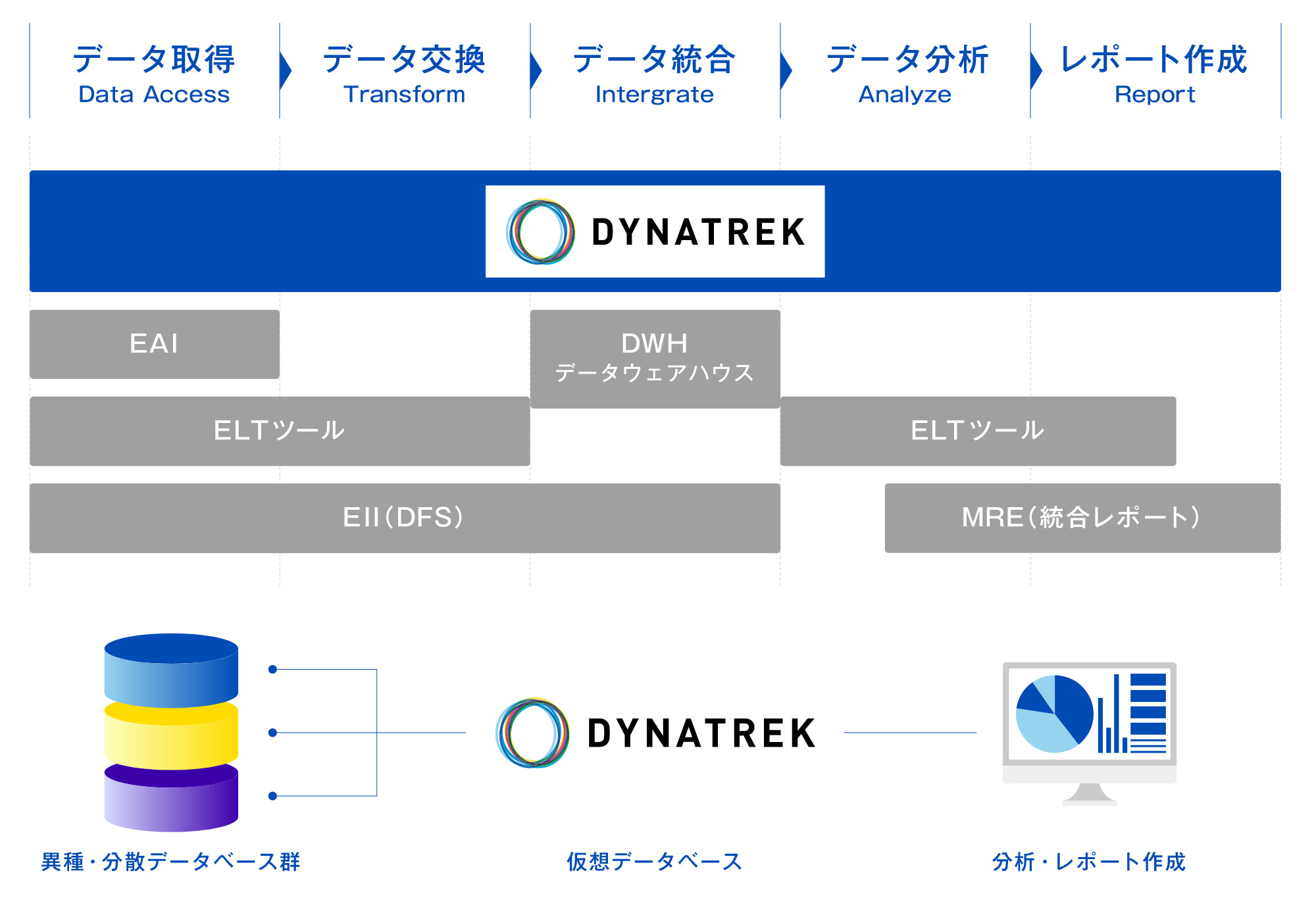
DYNATREK の仮想DB(仮想データベース)を用いることにより、複数のデータベースからの情報を一つに統合したり、データベースに格納されている素データをユーザ業務に即した情報に加工編集したりすることができるため、ユーザは複雑なデータベースの構造を意識することなく、必要なデータを自在に手に入れることができます
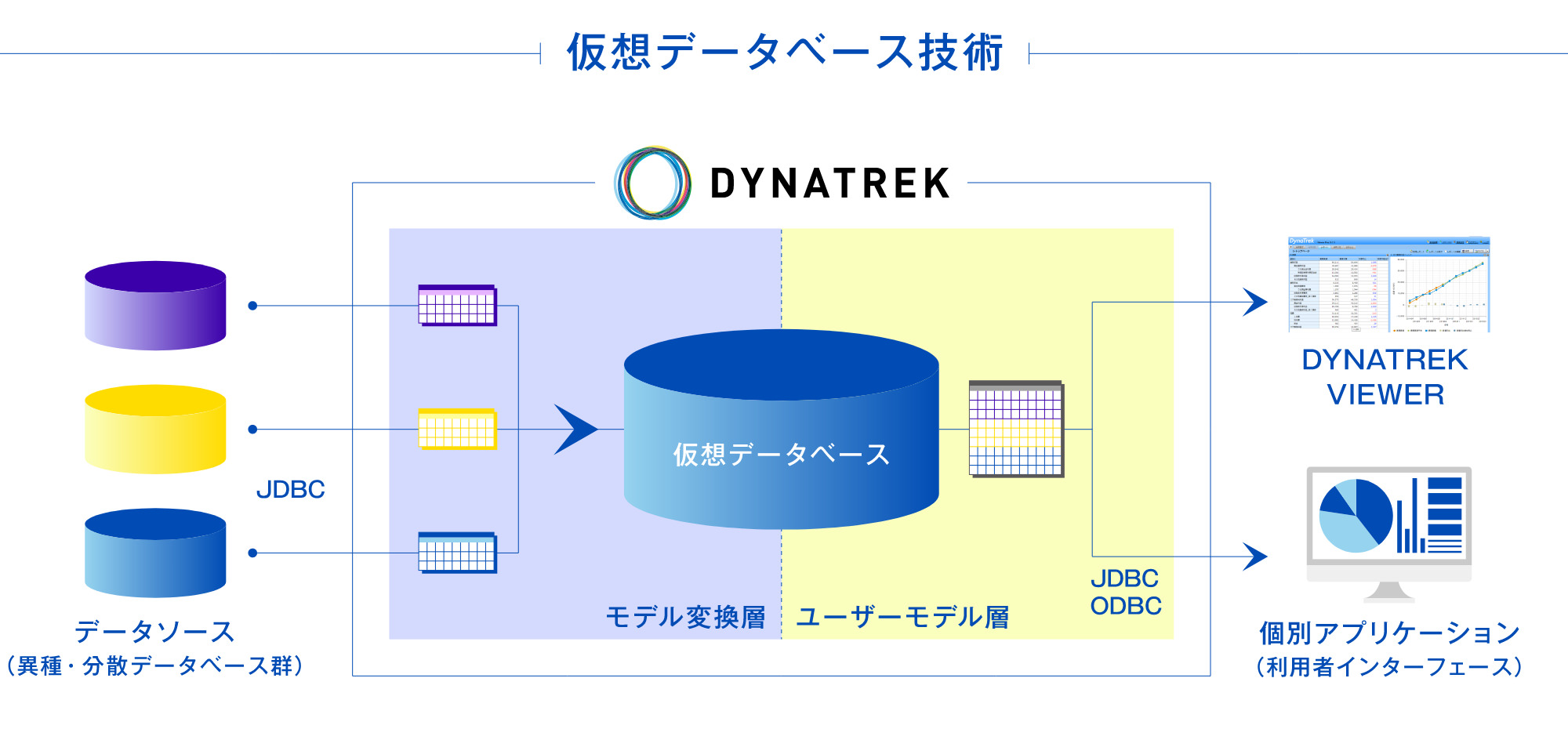
利用者インターフェイス
利用者は、DYNATREK の提供する利用者インターフェイスを経由して、仮想データベースにアクセスします。エンドユーザ向けのツールとして、専用のBI ツールであるDYNATREK Viewer があります。また、アプリケーション・プログラムからJDBC やODBCを経由して、DYNATREKの仮想データベースを一般のデータベース・エンジンと同じように利用することができます。さらに、DYNATREKの検索結果を別のデータベースに格納することもできます。
仮想データベース
DYNATREKでは、ユーザが利用する情報の種類や形式が定義されている仮想データベースを経由して、実際のデータベースを検索します。仮想データベースは、各種の定義やルールを持つだけのあくまでも論理的なものであり、実際のデータは実行時に必要なデータだけをもとに仮想的かつリアルタイムに作られます。したがって、データウェアハウスのようなデータの再構成作業が不要で、データ生成のタイムラグがないため最新の生きたデータを取得できる利点を有しています。仮想データベースは、ユーザ層とモデル変換層の2 つの層から構成されます。
ユーザモデル層
ユーザ層は、利用者からの検索コマンドを受け取って、それに対する検索結果データを返します。ユーザ層はデータ利用の視点から定義される、あくまでも論理的なものであるため、実際のデータベースのデータ構造とは独立に、ビジネスの体系や用語に沿った簡潔で分かりやすい構造とすることができます。
モデル変換層
モデル変換層は、ユーザ層の論理モデルとデータソースの物理構造を変換する機能をもち、利用者からの検索コマンドに基づき複数のデータソースから必要なデータを検索して、ユーザ層で定義されている情報に加工・編集するための一連の処理を行います。
データソース
DYNATREKは、複数のデータベースや異種のデータベース・エンジンを同時に扱うことができます。DYNATREK は検索対象のデータソース(既存のデータベースなど)に対して、JDBC を経由して検索指示(SQL)を発行し、検索結果のデータを取得します。DYNATREKはデータソースに対して検索を行うだけで、書き込み等は一切行いません。(DYNATREKで設定された仮想データベース設定をバッチ化し、データマートなどへ出力することは可能です)
仮想データベースのメリット
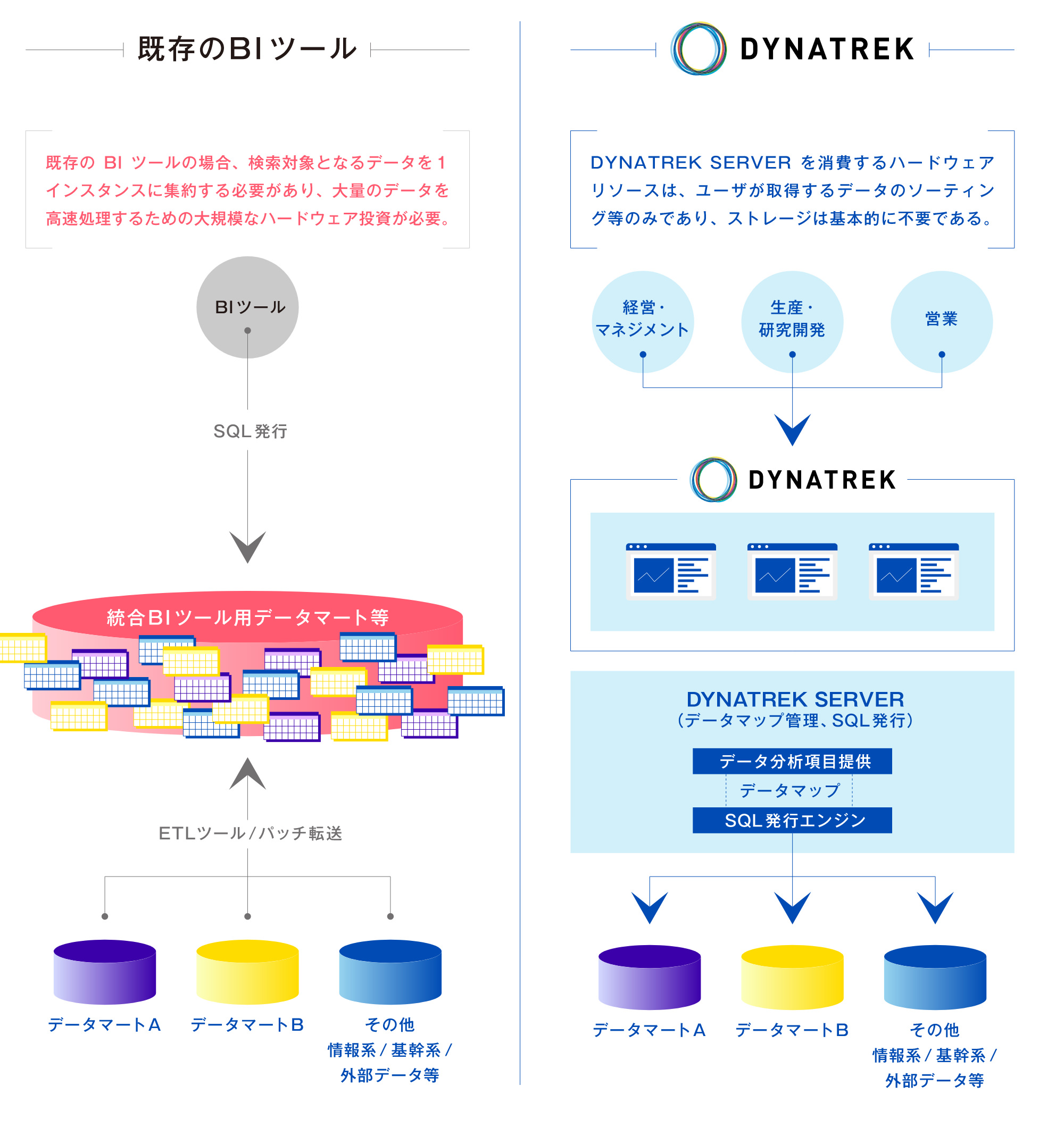
簡単・容易なシステム導入
DYNATREKは利用データを動的に自動生成するため、あらかじめ中間データを用意しておく必要がありません。データベースの初期化、データ投入等の構築作業が不要になり、システム導入の時間と手間を大きく削減することができます。
「生きている」最新データの取得が可能
中間データベースの更新は大変時間がかかるため定期的にバッチ処理され、ユーザは更新時点までの過去データしか利用できません。一方DYNATREK では、最新の「生きている」データもデータソースからリアルタイムで取得することができます。(基幹システムなど、セキュリティやその他システム要件によりJDBC での直接参照が難しいDBを検索対象とする場合、DBMS 機能によるレプリケーションを行うことを推奨しています。)
システム構築コストの大幅削減
従来のデータ統合では、ETL ツール、BI ツール等の他に、中間データベース用の高性能なハードとソフトが必要でした。DYNATREKは単独で必要機能を全て備え、かつ必要データだけを効率よく処理するため余分なリソースが不要で、システム構築コストを大幅削減します。
データ統合の選択肢
複数の異なるコンピュータ・システムのデータをもとに情報を取得するコンピュータ・システムの統合ニーズは、例えば販売・物流・生産など異なる業務システム間の統合、商品・事業部・関連会社などをまたがる横断的データ活用、企業の吸収・合併など、ビジネスのあらゆるシーンで頻繁に発生しています。このようなニーズに対応するために、従来から様々な方法が用いられてきました。
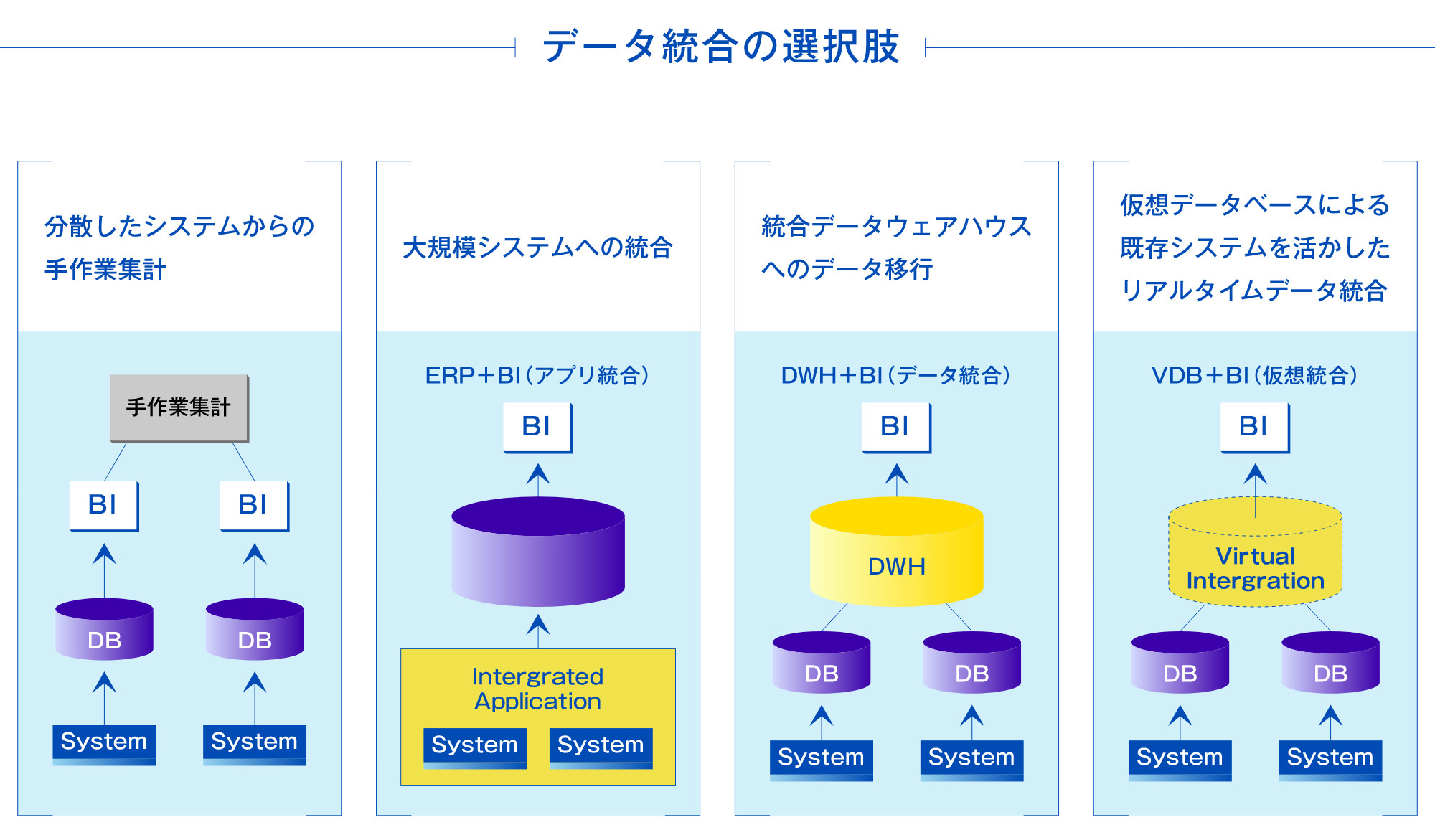
システム統合(ビッグバン)型アプローチ(ERPの導入)
このような統合のニーズに対して、従来はもっとも一般的だったのは、既存部分も含めて新たにソフトウェアを開発して対応する方法でした。しかし、異なるシステムのデータを扱うプログラムを作成するのは技術的に大変難しく、また開発が大規模となるためコストが高く、さらに旧システムから新システムへの移行リスクも伴うため、きわめて困難であるとされてきました。
データ統合(データウェアハウス)型アプローチ(統合データウェアハウスの導入)
近年、システムそのものではなくデータだけを統合する手法として、単一の統合データベースを別途構築し様々なデータを定期的に収集して集中管理する、データウェアハウスやデータマートといった方法を採用することも多くなってきました。しかし通常は、もとのデータベースの構造や内容がバラバラで不揃いなため、統合データベースにデータを投入する際に変換処理が必要となり、大量データの変換・更新処理に多大な時間と手間を要していました。また、システムが複雑で機能改善や変更時の作業が大変である、通常はバッチ更新であるため最新データが得られないなど、多くの課題点を有しています。
ミドルウェア(仮想データベース)型アプローチ(DYNATREKの導入)
これに対して、データ変換や検索に必要な機能をすべて包含したミドルウェアを利用することにより、既存のシステムやデータベースはそのまま生かしつつ、必要なときに必要なデータだけを統合することができるようになります。この方法は、データウェアハウスのような巨大な統合データベースを構築する必要がないため、導入が簡単・迅速で、変化にも柔軟に対応でき、かつ最新のデータも容易に取得できるという大きなメリットを有しています。